FireRedTTS-2
Long-form Streaming Text-to-Speech System for Multi-speaker Dialogue Generation
System Overview
FireRedTTS-2 is the second-generation text-to-speech system launched by the FireRed team of Xiaohongshu, designed specifically for multi-speaker dialogue generation. The system provides stable and natural voice output while achieving reliable speaker switching and context-aware prosody control.
Feature Introduction Screenshots
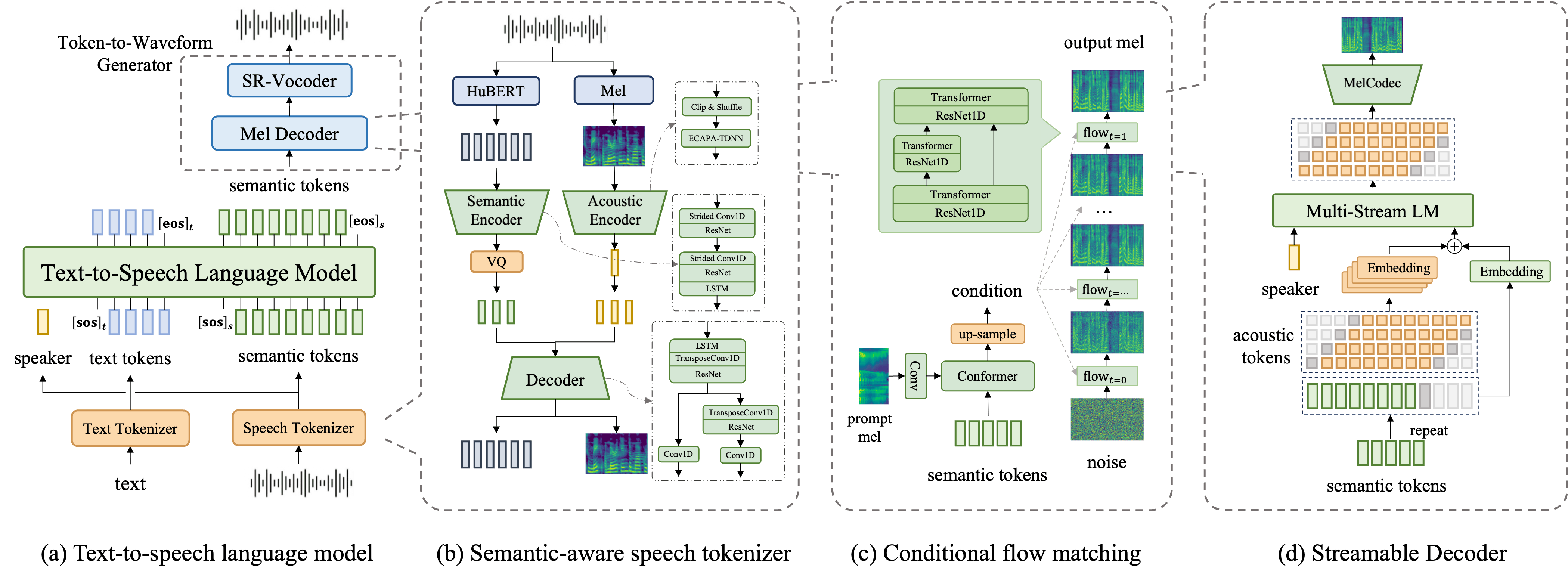
Core Improvements
Long-form Streaming Synthesis
Supports streaming speech synthesis of long-form content to reduce latency and improve user experience
Multi-speaker Dialogue
Optimized for multi-speaker dialogue scenarios to achieve natural speaker switching
Context-aware Prosody
Automatically adjusts voice prosody according to dialogue context to make output more natural
Enhanced Stability
Improved system architecture ensures long-term operational stability and consistency
Technical Advantages
- Streaming Decoder: Supports real-time streaming speech synthesis, suitable for dialogue systems
- Speaker Embedding Optimization: Improved speaker representation method for more reliable speaker switching
Application Scenarios
AI Podcast Production
Automatically generate multi-character dialogue podcast content, supporting different character voices
Virtual Meetings
Provide multi-speaker speech synthesis capabilities for virtual meeting systems
- Context Modeling: Enhanced context understanding capabilities to generate more context-appropriate speech
- End-to-End Training: Complete end-to-end training process, simplifying deployment and usage
Dialogue Systems
Provide more natural dialogue speech for chatbots and virtual assistants
Audioplay Production
Quickly generate multi-character audioplay content, improving production efficiency
Comparison with FireRedTTS-1
| Feature | FireRedTTS-1 | FireRedTTS-2 |
|---|---|---|
| Main Application Scenario | Single-speaker voice synthesis | Multi-speaker dialogue generation |
| Synthesis Method | Batch processing synthesis | Streaming synthesis |
| Speaker Switching | Basic support | Optimized support |
| Context Awareness | Limited support | Deep support |
| Long-form Content Processing | Segmented processing | Continuous streaming processing |