FireRedTTS-1
Basic Text-to-Speech System
FireRedTTS-1
First version released in September 2024, FireRedTTS is a basic text-to-speech system that supports zero-shot voice cloning and emotional voice generation.
Current VersionFireRedTTS-2
Latest FireRedTTS-2 features: Long dialogue voice generation, supporting 4-minute, 4-character dialogue.
View New VersionSystem Overview
FireRedTTS-1 is the first open-source text-to-speech system launched by the FireRed team of Xiaohongshu, built on large language model technology. The system can achieve high-quality speech synthesis, supporting zero-shot voice cloning and emotional voice generation functions.
Core Technical Features
Semantic-Aware Tokenizer
Uses a semantic-aware speech tokenizer (SAST) to compress speech signals into discrete tokens, improving synthesis quality
Two-Stage Generation
Text-to-semantic tokens to waveform two-stage generation system, ensuring high-quality output
Zero-Shot Cloning
Only a few seconds of reference audio is needed to mimic any voice and speaking style
Emotional Expression
Supports multiple emotional expressions and rich paralinguistic feature generation
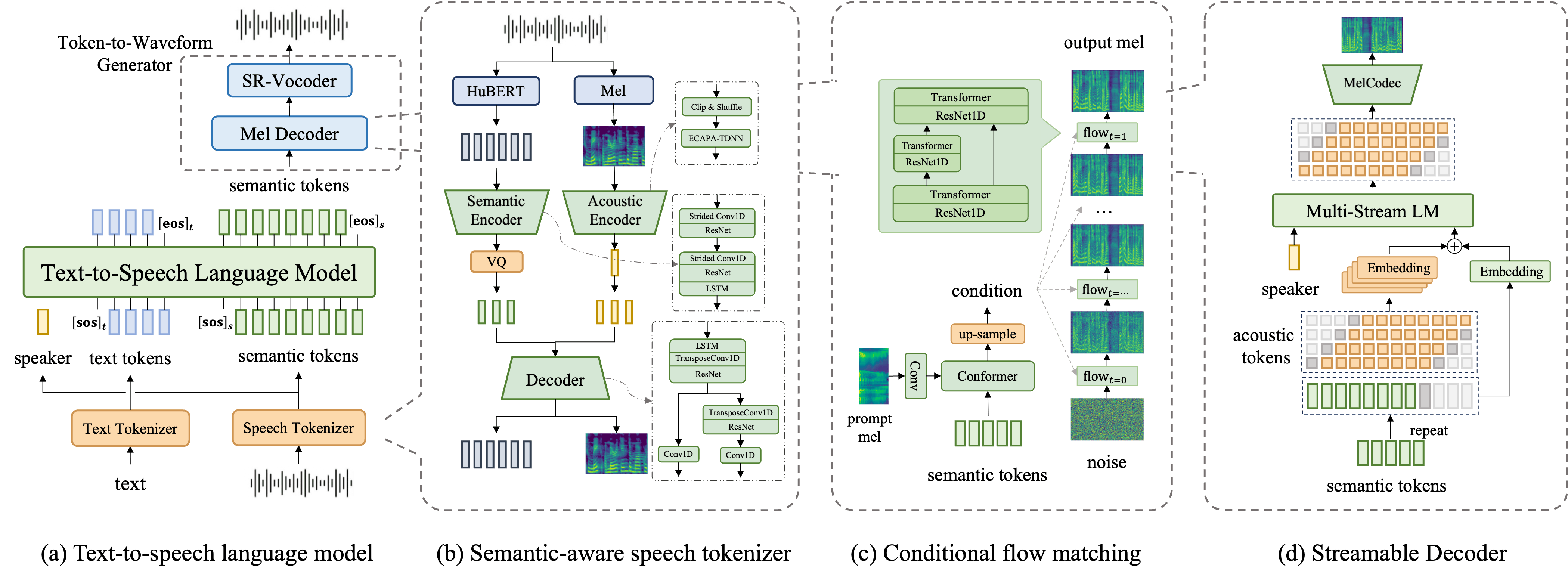
Technical Architecture
FireRedTTS-1 adopts a language model-based basic TTS system architecture, mainly including three modules:
- Speech Tokenizer: Converts speech signals into discrete semantic tokens
- Text-to-Speech Language Model: Maps text tokens to semantic tokens
- Token-to-Waveform Generator: Converts semantic tokens into final audio waveforms
Application Scenarios
Video Dubbing
Provides personalized speech synthesis for short videos, educational content, etc.
Virtual Assistant
Provides natural speech output for intelligent customer service, voice assistants, and other applications
Audiobooks
Quickly generates high-quality audiobook content