FireRedTTS
小紅書開源的先進文本轉語音系統
基於大語言模型,支援零樣本語音克隆和情感語音生成
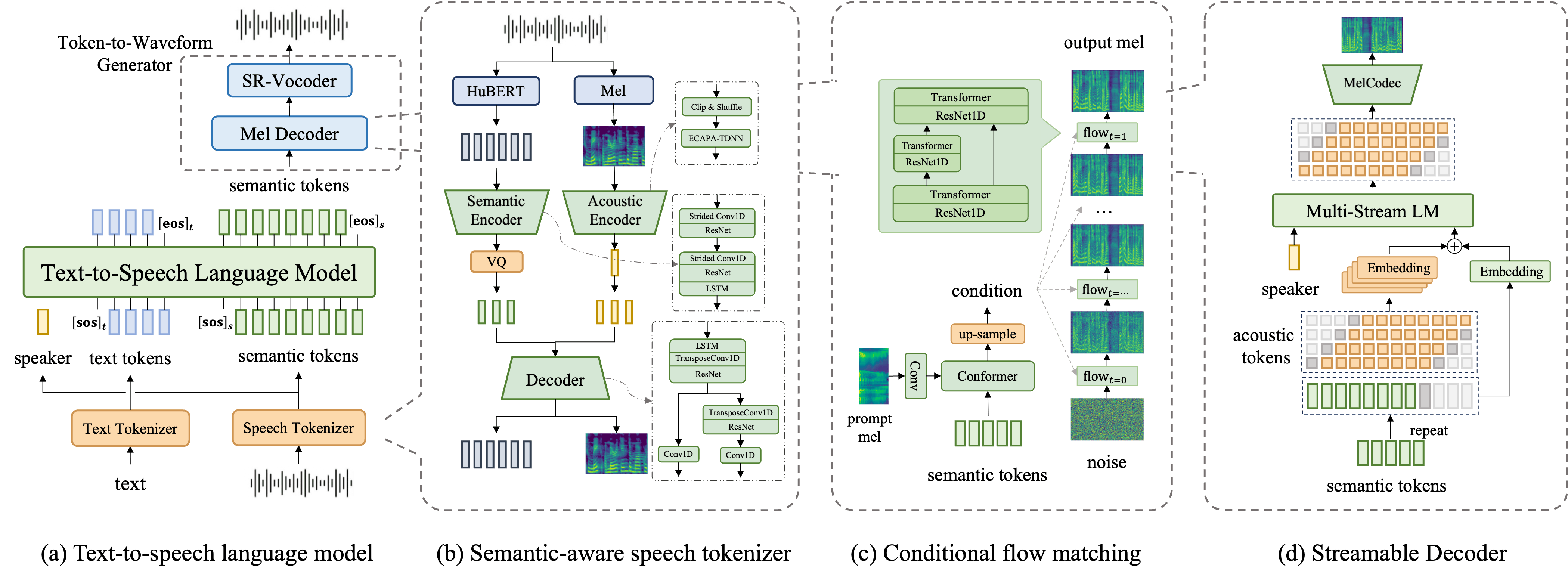
核心特性
零樣本語音克隆
僅需幾秒鐘的參考音頻即可模仿任意音色和說話風格
情感語音生成
支援多種情緒表達(憤怒、快樂、悲傷等)和豐富的副語言特徵
多語言支援
支援中文、英文及中英混合文本處理
流式解碼
支援流式語音合成,降低延遲,提升用戶體驗
功能介紹截圖
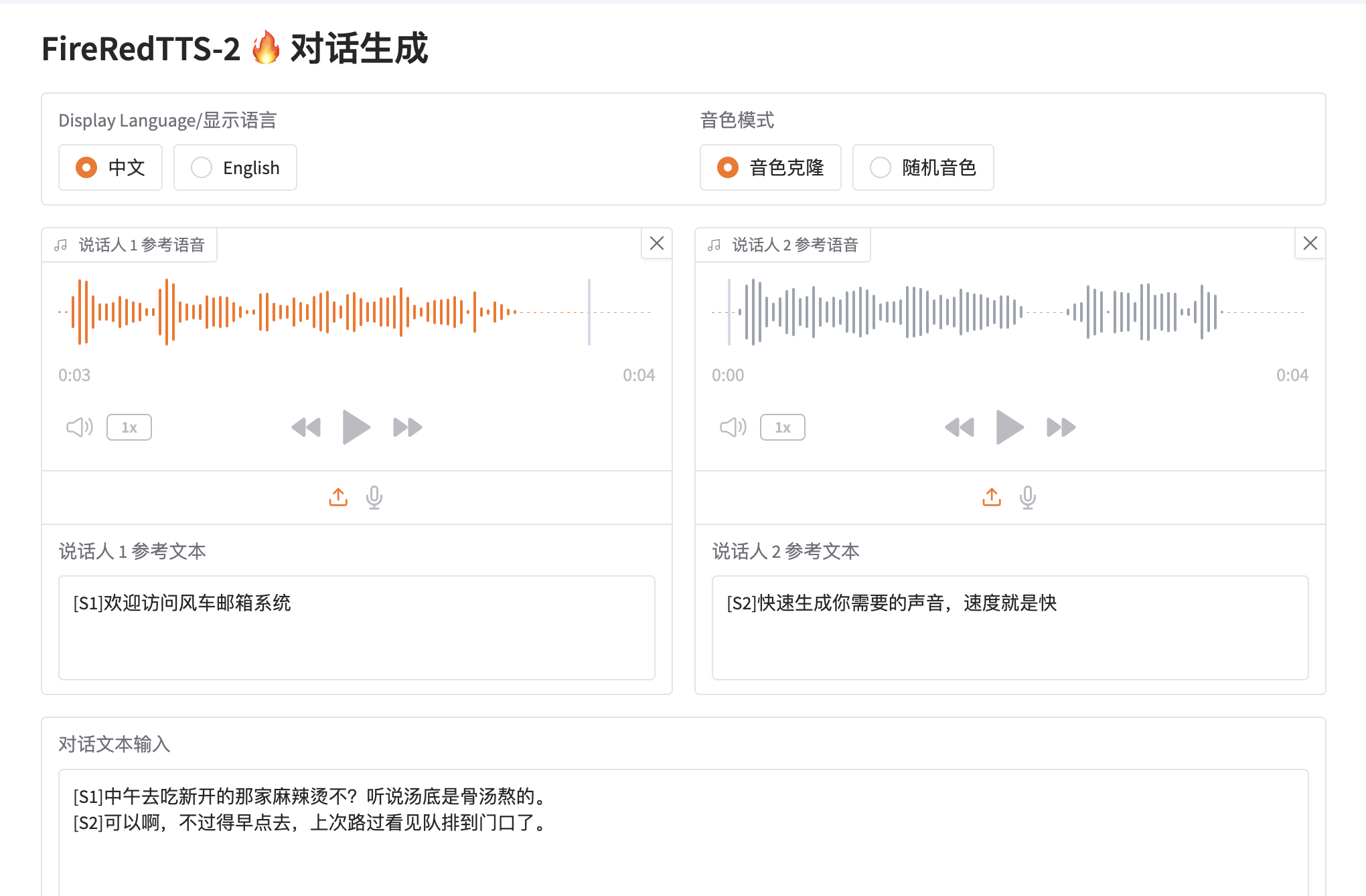
FireRedTTS-2 最新版本
面向多說話者對話生成的長篇流式文本轉語音系統
FireRedTTS-2是小紅書FireRed團隊推出的第二代文本轉語音系統,專為多說話者對話生成設計。該系統提供穩定、自然的語音輸出,同時實現可靠的說話人切換和語境感知的韻律控制。
核心亮點
- 長篇流式合成:支援長篇內容的流式語音合成,降低延遲,提升用戶體驗
- 多說話者對話:專為多說話者對話場景優化,實現自然的說話人切換
- 語境感知韻律:根據對話語境自動調整語音韻律,使輸出更加自然
- 增強穩定性:改進的系統架構確保長時間運行的穩定性和一致性
演示示例
多角色對話
展示不同角色之間的自然對話轉換
演示音頻 (佔位)
情感表達
展現豐富的情感語音生成能力
演示音頻 (佔位)
流式合成
即時流式語音合成效果展示
演示音頻 (佔位)
常見問題 (FAQ)
FireRedTTS是開源的嗎?
+是的,FireRedTTS完全開源,基於MIT許可證發布。您可以在GitHub上找到完整的原始碼,並根據需要自由使用、修改和分發。
FireRedTTS支援哪些作業系統?
+FireRedTTS支援Windows、Linux和macOS主流作業系統。我們提供了詳細的安裝指南,幫助您在不同平台上快速部署。
FireRedTTS-1和FireRedTTS-2有什麼區別?
+FireRedTTS-2是第二代版本,專為多說話者對話生成設計,支援長篇流式合成、語境感知韻律控制,並增強了系統穩定性。相比第一代,性能和自然度都有顯著提升。
需要多少參考音頻才能生成個人化語音?
+FireRedTTS採用零樣本語音克隆技術,僅需幾秒鐘(通常3-5秒)的參考音頻即可生成高品質的個人化語音,無需複雜的訓練過程。
FireRedTTS支援哪些語言?
+FireRedTTS支援中文、英文及中英混合文本處理。我們正在持續擴展語言支援,未來將支援更多語種。
如何獲取技術支援?
+您可以通過GitHub Issues提交問題,或加入我們的開發者社區獲取幫助。我們也提供詳細的文檔和教程,幫助您快速上手。