FireRedTTS
Advanced open-source text-to-speech system by Xiaohongshu
Based on large language models, supporting zero-shot voice cloning and emotional voice generation
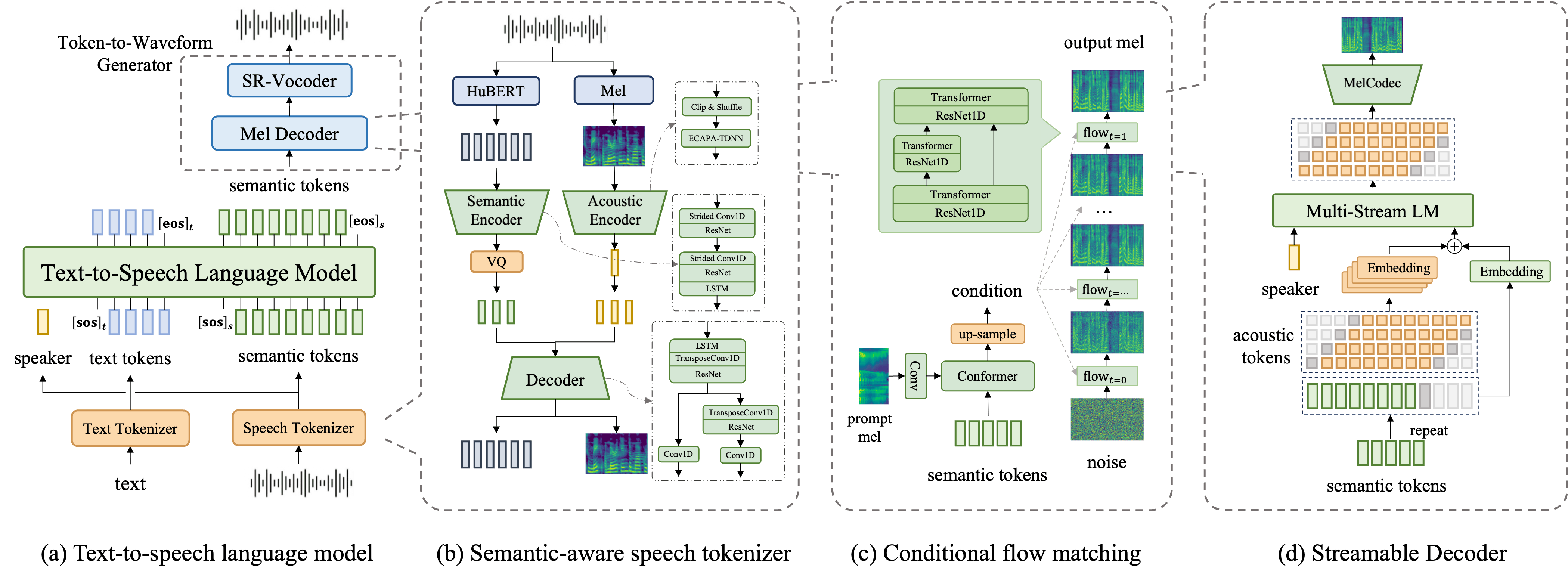
Core Features
Zero-shot Voice Cloning
Only a few seconds of reference audio is needed to mimic any voice and speaking style
Emotional Voice Generation
Supports multiple emotional expressions (anger, happiness, sadness, etc.) and rich paralinguistic features
Multilingual Support
Supports Chinese, English and Chinese-English mixed text processing
Streaming Decoding
Supports streaming speech synthesis to reduce latency and improve user experience
Feature Screenshots
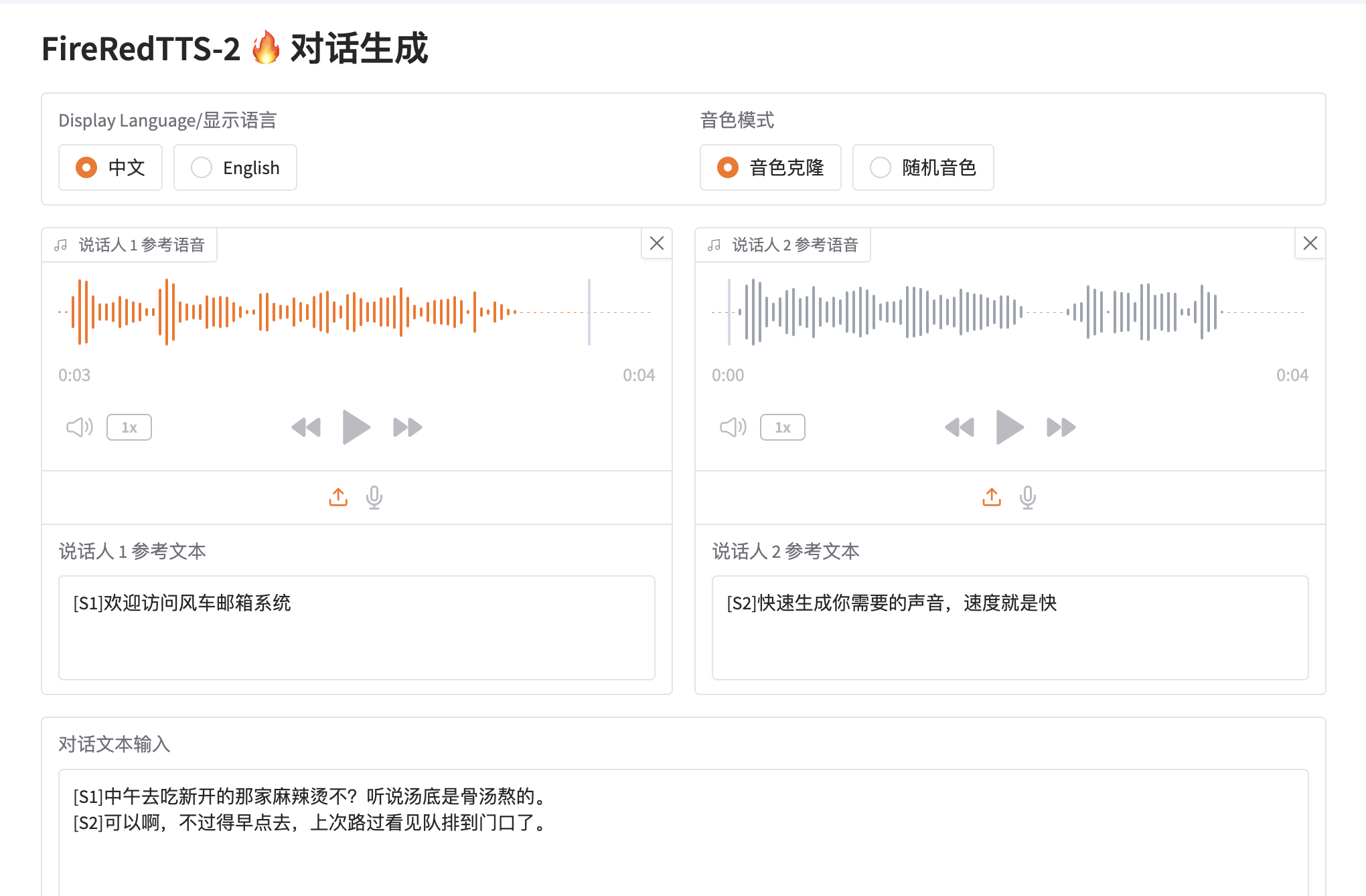
FireRedTTS-2 Latest Version
Long-form Streaming Text-to-Speech System for Multi-speaker Dialogue Generation
FireRedTTS-2 is the second-generation text-to-speech system launched by the FireRed team of Xiaohongshu, designed specifically for multi-speaker dialogue generation. The system provides stable and natural voice output while achieving reliable speaker switching and context-aware prosody control.
Core Highlights
- Long-form Streaming Synthesis: Supports streaming speech synthesis of long-form content to reduce latency and improve user experience
- Multi-speaker Dialogue: Optimized for multi-speaker dialogue scenarios to achieve natural speaker switching
- Context-aware Prosody: Automatically adjusts voice prosody according to dialogue context to make output more natural
- Enhanced Stability: Improved system architecture ensures long-term operational stability and consistency
Demo Examples
Multi-character Dialogue
Showcase natural dialogue transitions between different characters
Demo Audio (Placeholder)
Emotional Expression
Showcase rich emotional voice generation capabilities
Demo Audio (Placeholder)
Streaming Synthesis
Real-time streaming speech synthesis effect demonstration
Demo Audio (Placeholder)
Frequently Asked Questions (FAQ)
Is FireRedTTS open source?
+Yes, FireRedTTS is completely open source and released under the MIT license. You can find the complete source code on GitHub and freely use, modify and distribute it as needed.
Which operating systems does FireRedTTS support?
+FireRedTTS supports mainstream operating systems including Windows, Linux and macOS. We provide detailed installation guides to help you deploy quickly on different platforms.
What are the differences between FireRedTTS-1 and FireRedTTS-2?
+FireRedTTS-2 is the second-generation version designed specifically for multi-speaker dialogue generation, supporting long-form streaming synthesis, context-aware prosody control, and enhanced system stability. Compared to the first generation, performance and naturalness have been significantly improved.
How much reference audio is needed to generate personalized voice?
+FireRedTTS uses zero-shot voice cloning technology, requiring only a few seconds (typically 3-5 seconds) of reference audio to generate high-quality personalized voice without complex training processes.
Which languages does FireRedTTS support?
+FireRedTTS supports Chinese, English and Chinese-English mixed text processing. We are continuously expanding language support and will support more languages in the future.
How to get technical support?
+You can submit questions through GitHub Issues or join our developer community for help. We also provide detailed documentation and tutorials to help you get started quickly.