FireRedTTS
小红书开源的先进文本转语音系统
基于大语言模型,支持零样本语音克隆和情感语音生成
核心特性
零样本语音克隆
仅需几秒钟的参考音频即可模仿任意音色和说话风格
情感语音生成
支持多种情绪表达(愤怒、快乐、悲伤等)和丰富的副语言特征
多语言支持
支持中文、英文及中英混合文本处理
流式解码
支持流式语音合成,降低延迟,提升用户体验
功能介绍截图
FireRedTTS-2 最新版本
面向多说话者对话生成的长篇流式文本转语音系统
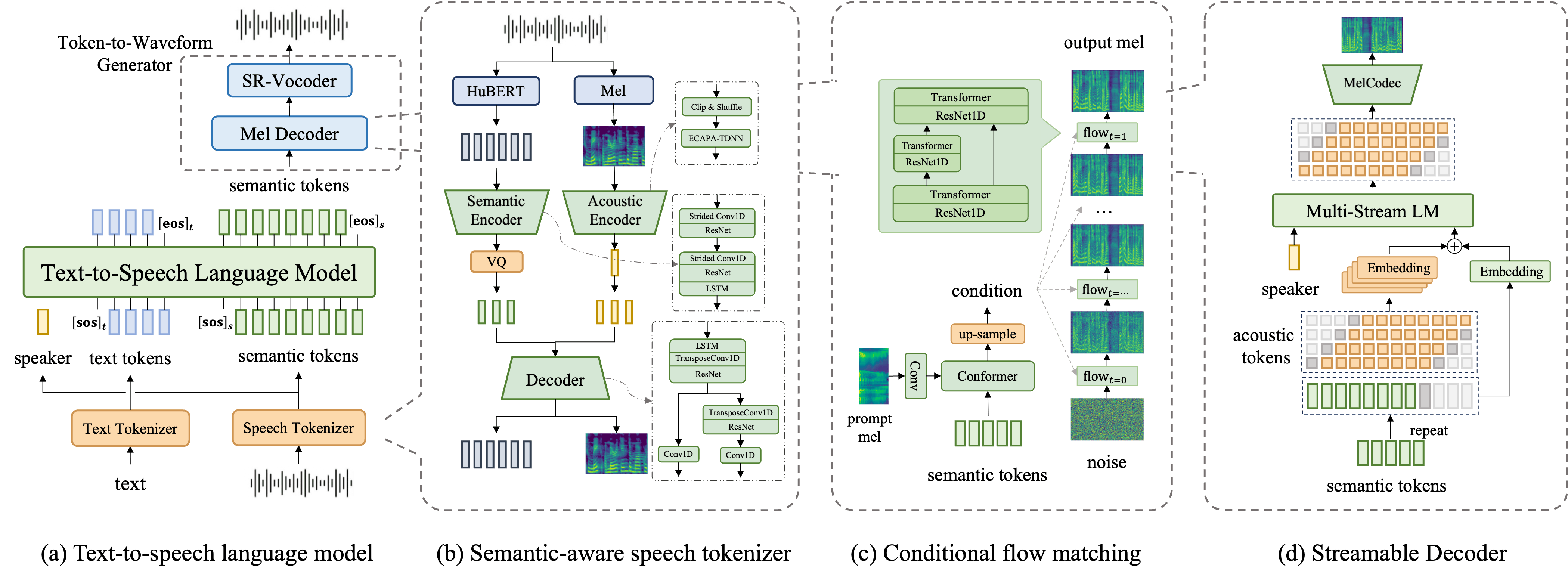
FireRedTTS-2是小红书FireRed团队推出的第二代文本转语音系统,专为多说话者对话生成设计。该系统提供稳定、自然的语音输出,同时实现可靠的说话人切换和语境感知的韵律控制。
核心亮点
- 长篇流式合成:支持长篇内容的流式语音合成,降低延迟,提升用户体验
- 多说话者对话:专为多说话者对话场景优化,实现自然的说话人切换
- 语境感知韵律:根据对话语境自动调整语音韵律,使输出更加自然
- 增强稳定性:改进的系统架构确保长时间运行的稳定性和一致性
演示示例
多角色对话
展示不同角色之间的自然对话转换
演示音频 (占位)
情感表达
展现丰富的情感语音生成能力
演示音频 (占位)
流式合成
实时流式语音合成效果展示
演示音频 (占位)
常见问题 (FAQ)
FireRedTTS是开源的吗?
+是的,FireRedTTS完全开源,基于MIT许可证发布。您可以在GitHub上找到完整的源代码,并根据需要自由使用、修改和分发。
FireRedTTS支持哪些操作系统?
+FireRedTTS支持Windows、Linux和macOS主流操作系统。我们提供了详细的安装指南,帮助您在不同平台上快速部署。
FireRedTTS-1和FireRedTTS-2有什么区别?
+FireRedTTS-2是第二代版本,专为多说话者对话生成设计,支持长篇流式合成、语境感知韵律控制,并增强了系统稳定性。相比第一代,性能和自然度都有显著提升。
需要多少参考音频才能生成个性化语音?
+FireRedTTS采用零样本语音克隆技术,仅需几秒钟(通常3-5秒)的参考音频即可生成高质量的个性化语音,无需复杂的训练过程。
FireRedTTS支持哪些语言?
+FireRedTTS支持中文、英文及中英混合文本处理。我们正在持续扩展语言支持,未来将支持更多语种。
如何获取技术支持?
+您可以通过GitHub Issues提交问题,或加入我们的开发者社区获取帮助。我们也提供详细的文档和教程,帮助您快速上手。